
2022-12-20 / There is a part 2 for this post available that contains an even faster implementation.
One of the joys of software development is that small changes can sometimes make solving the same problem orders of magnitude faster. I experienced this recently when implementing a function to generate a hash over multiple columns in a dataframe. Today I’m going to show you how I came up with that solution.
Before we get into the nitty-gritty details, let’s talk about the why first - why would you want to hash multiple columns in a dataframe? To ensure we’re all on the same page, let’s recap what a dataframe is. A dataframe is a table with columns and rows or, more formally, a two-dimensional data structure with labeled columns. A hash results from applying a hash function to a piece of data. It has a fixed length, and you’ll always receive the same hash if you input the same data into the hash function. You’ll receive a completely different hash if you input slightly different data. Getting the same hash from different inputs (“hash-collision”) is extremely unlikely.
These properties make hashes a good candidate for creating a unique identifier for a row in a dataframe. Often, rows are uniquely identified by a combination of columns, and it’s just a hassle always to use all these attributes when referencing a record. A hash over the column values that identify the row creates a convenient single identifier for the record.
To create a hash over multiple columns, we concatenate the values in these columns, feed them into a hash function, and store the output. It’s important to add a separator between the values. Otherwise, you may run into problems when one of the values is empty:
|0|1| |0| -> hash("010") -> a
|0| |1|0| -> hash("010") -> a
Here, empty columns at different positions lead to the same hash because there is no separator. This is easily solved with “:” as a separator:
|0|1| |0| -> hash("0:1::0") -> a
|0| |1|0| -> hash("0::1:0") -> b
For the initial implementation, correctness was more important than performance in the beginning because calculating the hash was only one step in a sequence of steps to achieve a business goal. We can ensure an implementation is correct enough by writing tests verifying the expected behavior. We won’t get formal proof that it works in all edge cases this way, but it’s good enough for us.
Before implementing my function, I decided on an interface it would use, i.e., the function name, inputs, and outputs, and then wrote a test case with well-known inputs and expected results. I calculated the expected hashes semi-manually using python and then hard-coded the expected hash values.
Next, I implemented a solution that made the test pass and seemed fine. Here is something similar to what I ended up with:
# DON'T USE THIS, IT'S SLOW!
class PandasApplyHasher0(AbstractHasher):
"""The original implementation"""
def hash(self) -> pd.DataFrame:
def hash_columns(row: pd.Series) -> str:
values = row[self.columns_to_hash]
pre_hash = HASH_FIELD_SEPARATOR.join(
str(value) for value in values)
hashed_values = HASH_FUNCTION(
pre_hash.encode("utf-8")).hexdigest()
return hashed_values
self.dataframe[self.target_column_name] = \
self.dataframe.apply(hash_columns, axis=1)
return self.dataframe
This class has a few attributes:
columns_to_hash- a list of columns to apply the hash function totarget_column_name- the name of the column in the resulting dataframe that contains the hashdataframethe dataframe to apply the hash function to
The implementation first defines an inner function called hash_columns, which is applied to the whole dataframe in the end. The inner function receives an individual row as a pandas series, then extracts the attributes needed from the hash from that series. Next, it joins them to a string with the separator after converting each value to a string. The result is fed into the hash function after being encoded as bytes using the utf-8 encoding.
This implementation is correct and works well enough on the small datasets I was using during the development of the business logic, so I moved on to implementing the many other steps to solve the business problem.
Problems started to arise when we tested this in the Lambda function with real data. Calculating the hashes of datasets with about 250k records took almost 190 seconds, a significant portion of the function runtime. This became a problem because we needed to calculate three different hashes for every dataset, and Lambda functions have a finite runtime of at most 15 minutes.
Throwing money at the problem (increasing memory and timeout) wasn’t sustainable. Since our metrics told me the problem was this implementation, I created a test setup to test different implementations on increasingly more extensive datasets. Let me take you through the implementation. First, I defined an abstract class that describes the interface the hashing implementations should adhere to:
import abc
import typing
import pandas as pd
class AbstractHasher(abc.ABC):
"""Interface for structured testing."""
dataframe: pd.DataFrame
target_column_name: str
columns_to_hash: typing.List[str]
num_records: int
def __init__(self, dataframe: pd.DataFrame,
columns_to_hash: typing.List[str], target_column_name: str) -> 'AbstractHasher':
self.dataframe = dataframe.copy()
self.target_column_name = target_column_name
self.columns_to_hash = columns_to_hash
self.num_records = len(dataframe)
def run_and_measure(self, n_times: int) -> None:
"""Run the Hasher n_times and log the runtimes."""
for _ in range(n_times):
hasher = self.__class__.__name__
log_msg = f"Run {hasher} with {self.num_records} records"
with log_and_record_runtime(log_msg, hasher, self.num_records):
self.hash()
@abc.abstractmethod
def hash(self) -> pd.DataFrame:
"""Hash the columns"""
It looks a bit messy, but the gist of it is this:
- The constructor (
__init__) takes the inputs for the hashing implementation and stores them as attributes in the class. It also creates a copy of the dataframe, so we don’t modify the original. This is work I don’t want/need to optimize, so it sits outside the implementation. - The method
run_and_measureperforms the hashingn_timeson the dataframe, logs the runtime of each invocation, and records it for later evaluation. - The method
hashhas theabstractmethodannotation, meaning any subclass has to overwrite it. This should be the concrete implementation of the hash function and return the dataframe with the additional hash column.
I also needed to make sure that each hasher implementation was correct. Otherwise, it would be pointless, so I adapted my test case from the original implementation like this:
def assert_hasher_is_correct(hasher_class: typing.Type[AbstractHasher]) -> None:
"""Assert that a given hasher computes the output we expect for known inputs."""
# Arrange
known_input = pd.DataFrame({
"int": [1, 2, 3],
"decimal": [Decimal("1.33"), Decimal("7"), Decimal("23.5")],
"bool": [True, False, True],
"date": [date.fromisoformat("2022-09-16"), date.fromisoformat("2022-04-13"),
date.fromisoformat("2022-09-16")],
"str": ["This", "Hasher", "Is_Correct"],
})
expected_df = known_input.copy()
expected_df["hashed"] = [
"c1551c906a6e8ebeecb91abbfd90db87264f1335cd4e855d3c8521b7c02c8c65",
"0afe31f8a139e9dfe7466989f7b4ffdb6504b150c81949f72bd96875b0ae91c4",
"073ccefe4bc389dd6b97321f5467305c910f14dfba58f4d75c9f9a67eed43514"
]
columns_to_hash = ["int", "decimal", "bool", "date", "str"]
target_column_name = "hashed"
# Act
hasher = hasher_class(
dataframe=known_input,
columns_to_hash=columns_to_hash,
target_column_name=target_column_name,
)
actual_df = hasher.hash()
# Assert
pandas.testing.assert_frame_equal(actual_df, expected_df)
LOGGER.info("Hasher %s is correct", hasher_class.__name__)
As the input, it takes a hasher class, i.e., a subclass of AbstractHasher. It first builds the input and expected output as well as the parameters. Next, it instantiates the hasher class, feeds in the input, and records the actual output. Last it uses the testing capabilities of pandas to ensure the actual result matches the expected outcome.
As the next part of my testing framework, I needed something that could generate dataframes with many rows. I ended up with this implementation:
import functools
import numpy as np
import pandas as pd
@functools.lru_cache(10)
def build_dataframe(n_rows: int) -> pd.DataFrame:
"""Builds a dataframe with 5 columns and n_rows rows that has a mix of columns."""
np.random.seed(42)
input_df = pd.DataFrame(
np.random.choice(['foo','bar','baz', Decimal("1.333"), 11, False], size=(n_rows, 5))
)
input_df = input_df.set_axis(['A', 'B', 'C', 'D', 'E'], axis=1, inplace=False)
LOGGER.info("Created dataframe with shape %s", input_df.shape)
return input_df
This creates a dataframe with a mix of datatypes, five columns, and an arbitrary number of rows. Setting the seed for the random function to a static value ensures we get the same dataframe each time. The functools.lru_cache annotation adds memoization, so we cache the results.
Now, we have all the major tools in place to implement different hashing methods. I tried other implementations and ended up with the following performance chart.
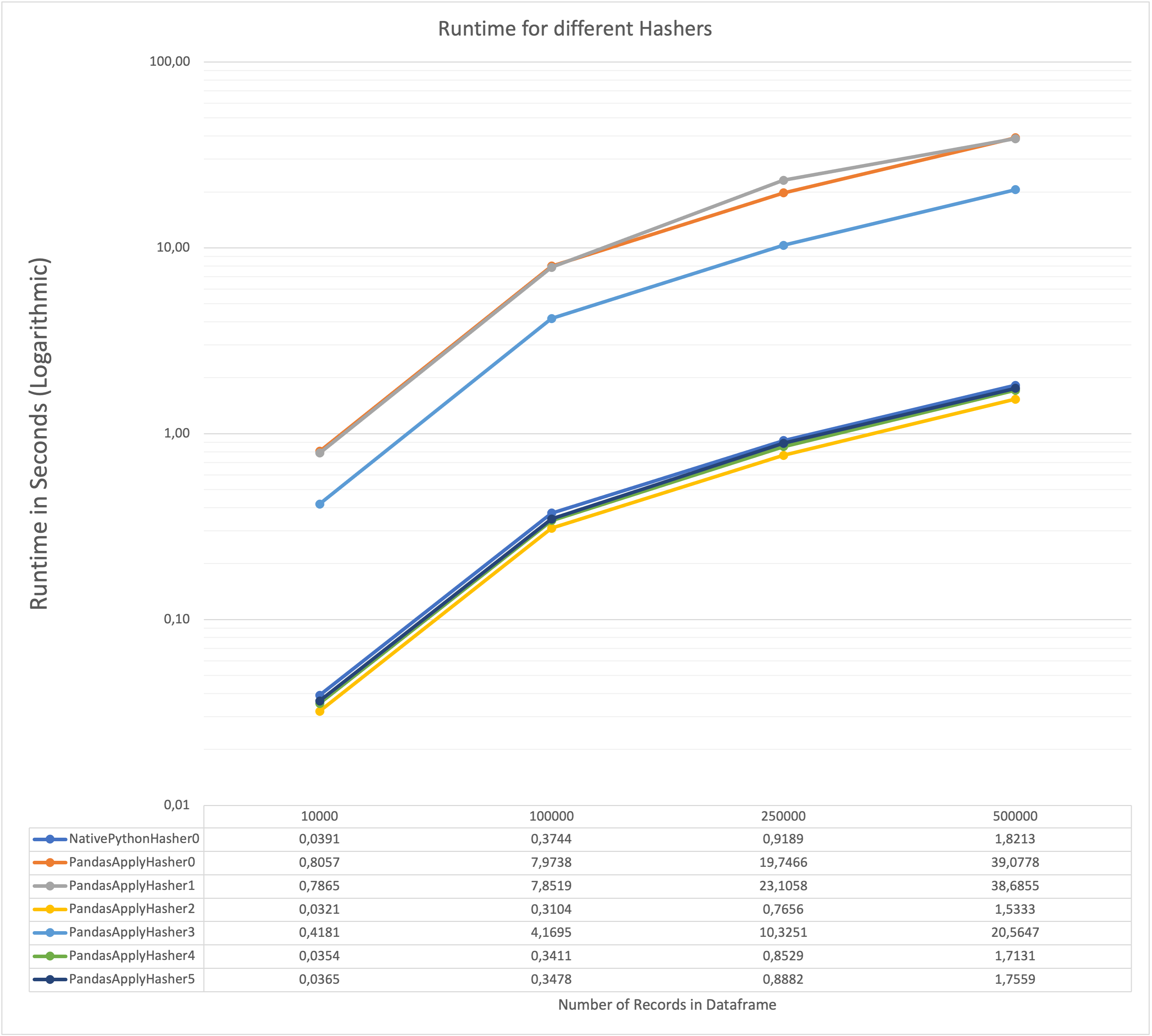
On the x-Axis, you can see the number of records that were hashed in that scenario, and the y-Axis shows the runtime in seconds. Beware that this is logarithmic, so each bold line means an increase of factor 10. All numbers were obtained on a MacBook Pro with the M1 Pro CPU.
It turns out that the fastest implementation is PandasApplyHasher2, which is about 25 times faster than the original implementation (PandasApplyHasher0). What makes this so much faster? Let’s take a look at the implementation.
class PandasApplyHasher2(AbstractHasher):
"""Avoid slicing from the dataframe many times."""
def hash(self) -> pd.DataFrame:
def hash_columns(row: pd.Series) -> str:
pre_hash = HASH_FIELD_SEPARATOR.join(map(str, row.to_list()))
hashed_values = HASH_FUNCTION(pre_hash.encode("utf-8")).hexdigest()
return hashed_values
# We run apply only on the columns relevant for the hash.
# This means we slice once and not n times.
self.dataframe[self.target_column_name] = \
self.dataframe[self.columns_to_hash].apply(hash_columns, axis=1)
return self.dataframe
The main difference is that we only apply hash_columns to the columns that are part of the hash, which means we don’t have to filter out the relevant attributes from the series n times and can use the whole series instead. Apparently, this slicing is not too efficient, so it makes sense to do it once and not n times. The other change is that I’m using map(str, ...) to convert everything into a string instead of the list comprehension, which appears to be slightly faster as well (albeit less readable, in my opinion).
So that’s it: two tiny changes make the implementation 25 times faster.
I learned a few things from this experience:
- Knowing your tools matters: While they provide the same output, using an implementation that aligns more with the tool’s design yields a significantly more efficient implementation.
- Not everything needs parallelization. That was our first approach to tackling this, but it’s not worth it if it can process 500k records in less than 2 seconds here.
- Metrics matter: We collected a few runtime metrics that allowed us to narrow down where the problem was happening quickly. This makes it possible to do very focused performance optimization.
- Trade-offs change over time. During development, I inadvertently traded off implementation speed for runtime performance. Once that became a problem, I responded by changing the implementation. Most of the time, that’s the right trade-off from an economic perspective (although that shouldn’t be the only perspective).
If you’re curious, you can check out the whole code for the performance testing setup and the different implementations on GitHub
— Maurice
2022-12-20 / There is a part 2 for this post available that contains an even faster implementation.
Title Photo by Jan Baborák on Unsplash