
A few months ago, I wrote an article outlining what I had learned from optimizing the process of creating a hash over multiple columns in a pandas Dataframe. I explained how I improved the speed of my original implementation by a factor of about 25. If you haven’t read that post, I suggest you do because this will only make sense in context. Long story short, I found an implementation that’s about 2.7 times faster than my former best result.
Before we get to that, here are a few reasons why I focused on this again. First of all, it’s fun, and I learned quite a bit in the past few months, which gave me a chance to focus more on pandas. The other reason is that my initial performance gains translated to the real world quite well in relative terms, but the absolute numbers are rising because the dataset is growing. The underlying hardware in AWS Lambda is slower than my local machine, and we have a computing-time budget of 15 minutes. Hashing is one of the things we do multiple times in each computation, so optimizing this process gives us more headroom for more meaningful computations and also saves money.
To simplify comparisons, I decided to state the results in terms of hashes per second, i.e., the number of rows pre-processed and hashed in a single second. Before we go into details, I’ll try to grab your attention by showing a pretty graph.
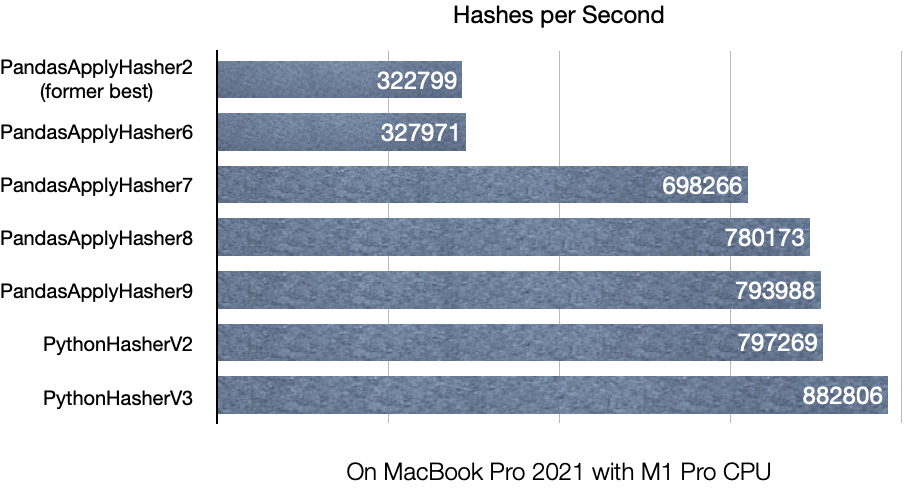
The best result from our first article managed around 320k hashes per second, which doesn’t sound too bad given that the first implementation managed around 12.8k hashes per second, which was already 25 times faster. The current best implementation manages around 880k hashes per second, about 2.7 times more than the previous best or 68 times faster than the original implementation.
The former best implementation PandasApplyHasher2 looks like this:
class PandasApplyHasher2(AbstractHasher):
"""Avoid slicing from the dataframe many times."""
def hash(self) -> pd.DataFrame:
def hash_columns(row: pd.Series) -> str:
pre_hash = HASH_FIELD_SEPARATOR.join(map(str, row.to_list()))
hashed_values = HASH_FUNCTION(pre_hash.encode("utf-8")).hexdigest()
return hashed_values
# We run the apply on only the columns relevant for the hash
# This means we slice once and not n times.
self.dataframe[self.target_column_name] = self.dataframe[
self.columns_to_hash
].apply(hash_columns, axis=1)
return self.dataframe
The next significant performance gain came with PandasApplyHasher7, where I decided to vectorize the string concatenation. This inspiration for this approach came from this answer on StackOverflow:
class PandasApplyHasher7(AbstractHasher):
"""
Like PandasApplyHasher6 but with sort-of vectorized string join
Inspired from https://stackoverflow.com/a/39293567/6485881
"""
def hash(self) -> pd.DataFrame:
def hash_series(input_bytes: bytes) -> str:
return HASH_FUNCTION(input_bytes).hexdigest()
# Convert the relevant values to string
df_with_str_columns = self.dataframe[self.columns_to_hash].astype(str)
# Add the separator to all but the last columns
df_with_str_columns.iloc[:, :-1] = df_with_str_columns.iloc[:, :-1].add(
HASH_FIELD_SEPARATOR
)
# Sum (in this case concat) all the values for each row and encode as bytes
encoded_series = df_with_str_columns.sum(axis=1).str.encode("utf-8")
# We run the apply on only the columns relevant for the hash
# This means we slice once and not n times.
self.dataframe[self.target_column_name] = encoded_series.apply(hash_series)
return self.dataframe
I also tried to vectorize both the conversion of the values to string as well as encoding them to bytes for the hash function. Turns out that the type conversion is pretty quick, but anything that uses .str.something on a series seems to be slower than the apply because the gains in PandasApplyHasher8 come from moving the encoding step into the inner function.
Another answer in the StackOverflow thread recommended trying an implementation that relies more on basic Python and leaves string conversion to pandas. PandasApplyHasher9 shows that this brought a modest performance boost.
class PandasApplyHasher9(AbstractHasher):
"""
Like PandasApplyHasher8 but with the encoding step in hash_series
Inspired from: https://stackoverflow.com/a/62135779/6485881
"""
def hash(self) -> pd.DataFrame:
def hash_series(input_str: str) -> str:
return HASH_FUNCTION(input_str.encode("utf-8")).hexdigest()
# Concat all Values in each row
hash_input_series = pd.Series(
map(
HASH_FIELD_SEPARATOR.join,
self.dataframe[self.columns_to_hash].astype(str).values.tolist(),
),
index=self.dataframe.index,
)
# We run the apply on only the columns relevant for the hash
# This means we slice once and not n times.
self.dataframe[self.target_column_name] = hash_input_series.apply(hash_series)
return self.dataframe
More Python and less Pandas seemed to be the way to go, so I decided to avoid all apply-calls and only used pandas for the string conversion. I moved the rest to an inner function, and that’s how I ended up with PythonHasherV3.
class PythonHasherV3(AbstractHasher):
"""
Like PythonHasherV2 but using itertuples instead of converting values to a list
"""
def hash(self) -> pd.DataFrame:
def hash_string_iterable(string_iterable: typing.Iterable[str]) -> str:
input_str = HASH_FIELD_SEPARATOR.join(string_iterable)
return HASH_FUNCTION(input_str.encode("utf-8")).hexdigest()
# Apply the hash_string_iterable to the stringified list of row values
hashed_series = pd.Series(
map(
hash_string_iterable,
self.dataframe[self.columns_to_hash]
.astype(str)
.itertuples(index=False, name=None),
),
index=self.dataframe.index,
)
self.dataframe[self.target_column_name] = hashed_series
return self.dataframe
I also switched over to itertuples, which reduced the memory footprint a bit (and was about 10% faster than the former implementation).
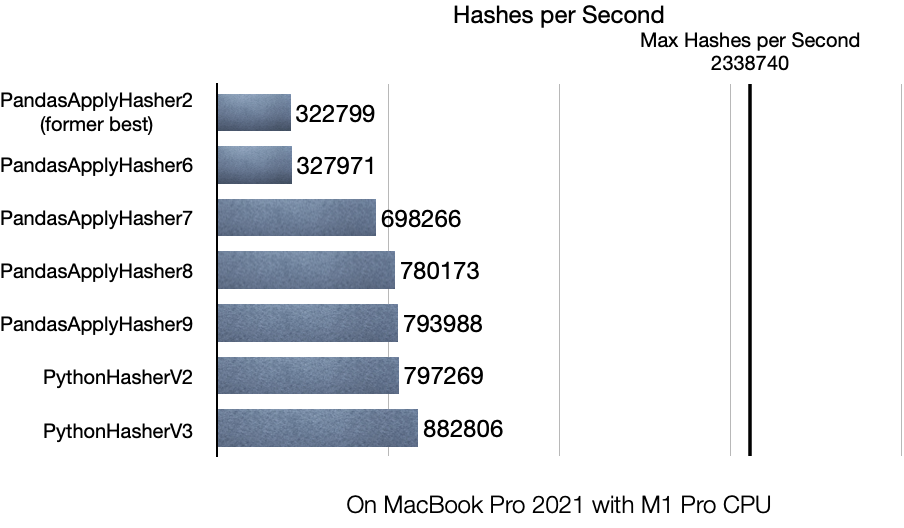
Naturally, the question arises if this is now the most efficient implementation possible. Probably not. I decided to figure out what the approximate maximum performance of the underlying hash function (sha256) is. The implementation is basic - it applies the hash function to a pandas series full of byte-encoded UUIDs. The idea is to find out how fast it could get if the cost of preparations is 0.
def calculate_max_hash_throughput(dataframe: pd.DataFrame) -> pd.Series:
"""Measures how many hashes per second we can do if all data is prepared."""
series = pd.Series(
data=(str(uuid.uuid4()).encode("utf-8") for _ in range(len(dataframe)))
)
with log_and_record_runtime(
"Max Hash Throughput", "max_hash_throughput", len(dataframe)
):
return series.apply(lambda x: HASH_FUNCTION(x).hexdigest())
Turns out that on my machine, the maximum hash throughput using sha256 from the standard library is about 2.3M per second. I’m aware this depends on many factors I’m not controlling for here, but it tells me there is probably more room for growth.
Conclusion
I learned a few things again:
- Try to avoid the
.str.operations for pandas Series and DataFrames if you’re working with hundreds of thousands or millions of records. They’re convenient but not especially fast. - Type conversions in pandas are relatively fast
- For operations that require the Python standard library to compute things, the overhead that the dataframe adds may decrease performance. In these cases, pure Python may be faster.
If you’re curious, you can find all of the code on Github.
Hopefully, my holiday project helps someone, cheers!
— Maurice
Title Photo by Jan Baborák on Unsplash